

First time machine translation has used true transfer learning
The gap between human and machine translators could be narrowing as researchers find a new way to improve the learning capabilities of Google Translate’s neural network.
On the same day that Google announced its translation services were now operating with its Neural Machine Translation (NMT) system, a team of researchers released a paper on arXiv showing how its NMT could be pushed one step further.
An NMT is a large single neural network that learns to translate by being trained on a pair of languages. Google Translate has been around for ten years, and before an NMT was used, it often provided a clumsy attempt at translation. Sentences could be lost in translation because individual phrases were translated together instead of whole sentences.
First, the encoder breaks down the sentence into its constituent words and represents the meaning as a vector.
The system interprets the whole sentence, and the decoder begins to translate each word by looking at the weighted distribution over the encoded vectors and matching them up to the most relevant words in the target language.
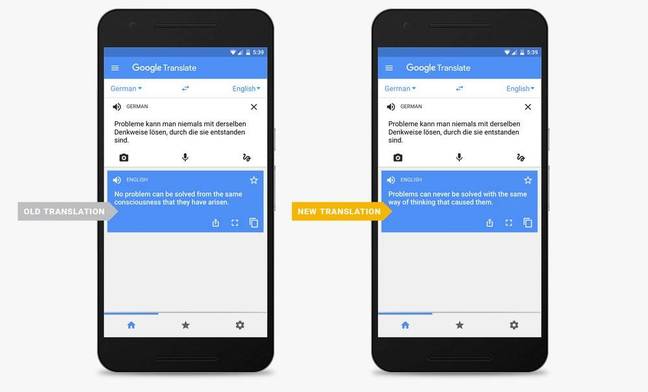
Google now promises to provide better translations that are “smoother and easier to read” for eight language pairs: English and French, German, Spanish, Portuguese, Chinese, Japanese, Korean and Turkish.
For many NMTs, the machine encodes the sentence into vectors by focusing on each word individually – something called the “attention mechanism.” Several attention mechanisms were required to cope with different languages, and multiple encoders and decoders are used for translation.
But when a single attention mechanism is used for multiple languages, the system can be coaxed into learning to translate between pairs of languages it hasn’t encountered before – something the researchers call “zero-shot translation.”
“For example, a multilingual NMT model trained with Portuguese→English and English→Spanish examples can generate reasonable translations for Portuguese→Spanish, although it has not seen any data for that language pair,” the paper said.
Interestingly, the researchers found evidence that the network was learning “some sort of shared representation,” where sentences with similar meaning were represented in similar ways regardless of language.
Training the model across multiple languages can enhance the performance of translating into individual languages, and the system can even cope better with sentences that are written in a mixture of languages.
Although the researchers only used a maximum of 12 language pairs for a single model, it would be easy to add more, and simple to use, as it operates on the same architecture as the NMT currently being used by Google Translate.
Zero-shot translation is the first time that “true transfer learning” has been shown to work for machine translation, according to the researchers.
Transfer learning is considered key to developing true machine intelligence, as systems must learn to deal with new situations based on knowledge gained from previous experiences. ®
On the same day that Google announced its translation services were now operating with its Neural Machine Translation (NMT) system, a team of researchers released a paper on arXiv showing how its NMT could be pushed one step further.
An NMT is a large single neural network that learns to translate by being trained on a pair of languages. Google Translate has been around for ten years, and before an NMT was used, it often provided a clumsy attempt at translation. Sentences could be lost in translation because individual phrases were translated together instead of whole sentences.
First, the encoder breaks down the sentence into its constituent words and represents the meaning as a vector.
The system interprets the whole sentence, and the decoder begins to translate each word by looking at the weighted distribution over the encoded vectors and matching them up to the most relevant words in the target language.
Google now promises to provide better translations that are “smoother and easier to read” for eight language pairs: English and French, German, Spanish, Portuguese, Chinese, Japanese, Korean and Turkish.
Photo credit: Google
But when a single attention mechanism is used for multiple languages, the system can be coaxed into learning to translate between pairs of languages it hasn’t encountered before – something the researchers call “zero-shot translation.”
“For example, a multilingual NMT model trained with Portuguese→English and English→Spanish examples can generate reasonable translations for Portuguese→Spanish, although it has not seen any data for that language pair,” the paper said.
Interestingly, the researchers found evidence that the network was learning “some sort of shared representation,” where sentences with similar meaning were represented in similar ways regardless of language.
Training the model across multiple languages can enhance the performance of translating into individual languages, and the system can even cope better with sentences that are written in a mixture of languages.
Although the researchers only used a maximum of 12 language pairs for a single model, it would be easy to add more, and simple to use, as it operates on the same architecture as the NMT currently being used by Google Translate.
Zero-shot translation is the first time that “true transfer learning” has been shown to work for machine translation, according to the researchers.
Transfer learning is considered key to developing true machine intelligence, as systems must learn to deal with new situations based on knowledge gained from previous experiences. ®
No comments:
Post a Comment